OpenAI震撼發布o1大模型 強化學習突破LLM推理極限
來源:機器之心
大語言模型還能向上突破,OpenAI再次證明了自己的實力。
北京時間9月13日午夜,OpenAI正式公開一系列全新AI大模型,旨在專門解決難題。這是一個重大突破,新模型可以實現復雜推理,一個通用模型解決比此前的科學、代碼和數學模型能做到的更難的問題。
奧特曼表示,雖然o1的表現仍然存在缺陷,不過你在第一次使用它的時候仍然會感到震撼。
其次,o1給大模型規模擴展vs性能的曲線帶來了一次上翹。它在大模型領域重現了當年AlphaGo強化學習的成功——給越多算力,就輸出越多能,一直到超越人類水平。
也就是從方法上,o1大模型首次證明了語言模型可以進行真正的強化學習。
開發出首個AI軟件工程師Devin的CognitionAI表示,過去幾周一直與OpenAI密切合作,使用Devin評估o1的推理能力。結果發現,與GPT-4o相比,o1系列模型對于處理代碼的智能體系統來說是一個重大進步。
最后在實踐中,o1上線之后,現在ChatGPT可以在回答問題前先仔細思考,而不是立即脫口而出答案。就像人類大腦的系統1和系統2,ChatGPT已經從僅使用系統1(快速、自動、直觀、易出錯)進化到了可使用系統2思維(緩慢、深思熟慮、有意識、可靠)。這讓它能夠解決以前無法解決的問題。
從今天ChatGPT的用戶體驗來看,這是向前邁進一小步。在簡單的Prompt下,用戶可能不會注意到太大的差異,但如果問一些棘手的數學或者代碼問題,區別就開始明顯了。更重要的是,未來發展的道路已經開始顯現。
總而言之,今晚OpenAI丟出的這個重磅炸彈,已經讓整個AI社區震撼,紛紛表示tql、睡不著覺,深夜已經開始抓緊學習。接下來,就讓我們看下OpenAIo1大模型的技術細節。OpenAIo1工作原理
在技術博客《LearningtoReasonwithLLMs》中,OpenAI對o1系列語言模型做了詳細的技術介紹。
OpenAIo1是經過強化學習訓練來執行復雜推理任務的新型語言模型。特點就是,o1在回答之前會思考——它可以在響應用戶之前產生一個很長的內部思維鏈。
也就是該模型在作出反應之前,需要像人類一樣,花更多時間思考問題。通過訓練,它們學會完善自己的思維過程,嘗試不同的策略,并認識到自己的錯誤。
在OpenAI的測試中,該系列后續更新的模型在物理、化學和生物學這些具有挑戰性的基準任務上的表現與博士生相似。OpenAI還發現它在數學和編碼方面表現出色。
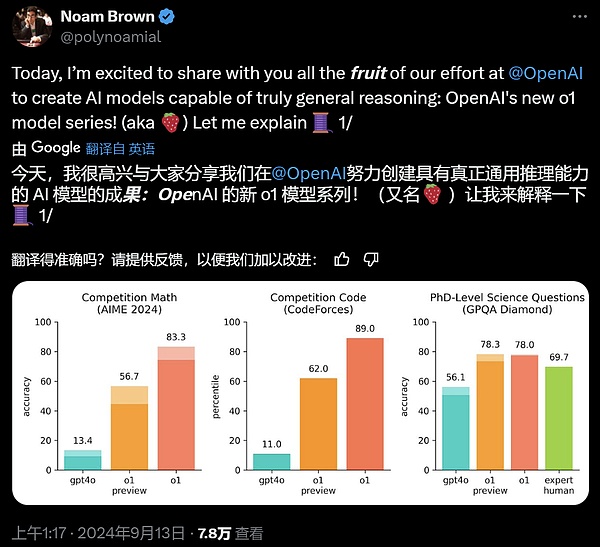
在國際數學奧林匹克(IMO)資格考試中,GPT-4o僅正確解答了13%的問題,而o1模型正確解答了83%的問題。
模型的編碼能力也在比賽中得到了評估,在Codeforces比賽中排名89%。
OpenAI表示,作為早期模型,它還不具備ChatGPT的許多實用功能,例如瀏覽網頁獲取信息以及上傳文件和圖片。
但對于復雜的推理任務來說,這是一個重大進步,代表了人工智能能力的新水平。鑒于此,OpenAI將計數器重置為1,并將該系列模型命名為OpenAIo1。
重點在于,OpenAI的大規模強化學習算法,教會模型如何在數據高度有效的訓練過程中利用其思想鏈進行高效思考。換言之,類似于強化學習的ScalingLaw。
OpenAI發現,隨著更多的強化學習(訓練時計算)和更多的思考時間(測試時計算),o1的性能持續提高。而且擴展這種方法的限制與大模型預訓練的限制有很大不同,OpenAI也還在繼續研究。
評估
為了突出相對于GPT-4o的推理性能改進,OpenAI在一系列不同的人類考試和機器學習基準測試中測試了o1模型。實驗結果表明,在絕大多數推理任務中,o1的表現明顯優于GPT-4o。
o1在具有挑戰性的推理基準上比GPT-4o有了很大的改進。
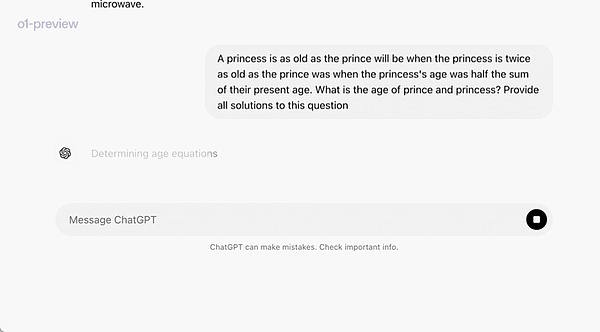
在一個官方演示中,o1-preview解答了一個非常困難的推理問題:當公主的年齡是王子的兩倍時,公主的年齡與王子一樣大,而公主的年齡是他們現在年齡總和的一半。王子和公主的年齡是多少?提供這個問題的所有解。
在2024年AIME考試中,GPT-4o平均只解決了12%(1.8/15)的問題,而o1在每個問題只有一個樣本的情況下平均為74%(11.1/15),在64個樣本之間達成一致的情況下為83%(12.5/15),在使用學習的評分函數對1000個樣本重新排序時為93%(13.9/15)。13.9分可以躋身全美前500名,并且高于美國數學奧林匹克競賽分數線。
OpenAI還在GPQADiamond基準上評估了o1,這是一個困難的智力基準,用于測試化學、物理和生物學方面的專業知識。為了將模型與人類進行比較,OpenAI聘請了擁有博士學位的專家來回答GPQADiamond基準問題。
實驗結果表明:o1超越了人類專家的表現,成為第一個在該基準測試中做到這一點的模型。
這些結果并不意味著o1在所有方面都比博士更有能力——只是該模型更擅長解決一些博士應該解決的問題。在其他幾個ML基準測試中,o1實現了新的SOTA。
啟用視覺感知能力后,o1在MMMU基準上得分為78.2%,成為第一個與人類專家相當的模型。o1還在57個MMLU子類別中的54個上優于GPT-4o。思維鏈(CoT)
與人類在回答難題之前會長時間思考類似,o1在嘗試解決問題時會使用思維鏈。通過強化學習,o1學會磨練其思維鏈并改進其使用的策略。o1學會了識別和糾正錯誤,并可以將棘手的步驟分解為更簡單的步驟。o1還學會了在當前方法不起作用時嘗試不同的方法。這個過程極大地提高了模型的推理能力。編程能力
基于o1進行了初始化并進一步訓練了其編程技能后,OpenAI訓練得到了一個非常強大的編程模型(o1-ioi)。該模型在2024年國際信息學奧林匹克競賽(IOI)賽題上得到了213分,達到了排名前49%的水平。并且該模型參與競賽的條件與2024IOI的人類參賽者一樣:需要在10個小時內解答6個高難度算法問題,并且每個問題僅能提交50次答案。
針對每個問題,這個經過專門訓練的o1模型會采樣許多候選答案,然后基于一個測試時選取策略提交其中50個答案。選取標準包括在IOI公共測試案例、模型生成的測試案例以及一個學習得到的評分函數上的性能。
研究表明,這個策略是有效的。因為如果直接隨機提交一個答案,則平均得分僅有156。這說明在該競賽條件下,這個策略至少值60分。
OpenAI發現,如果放寬提交限制條件,則模型性能更是能大幅提升。如果每個問題允許提交1萬次答案,即使不使用上述測試時選取策略,該模型也能得到362.14分——可以得金牌了。
最后,OpenAI模擬了Codeforces主辦的競爭性編程競賽,以展示該模型的編碼技能。采用的評估與競賽規則非常接近,允許提交10份代碼。GPT-4o的Elo評分為808,在人類競爭對手中處于前11%的水平。該模型遠遠超過了GPT-4o和o1——它的Elo評分為1807,表現優于93%的競爭對手。
 人類偏好評估
人類偏好評估
除了考試和學術基準之外,OpenAI還在更多領域的具有挑戰性的開放式提示上評估了人類對o1-preview和GPT-4o的偏好。
在這次評估中,人類訓練者對o1-preview和GPT-4o的提示進行匿名回答,并投票選出他們更喜歡的回答。在數據分析、編程和數學等推理能力較強的類別中,o1-preview的受歡迎程度遠遠高于GPT-4o。然而,o1-preview在某些自然語言任務上并不受歡迎,這表明它并不適合所有用例。
在需要更強大推理能力的領域,人們更青睞o1-preview。安全
思維鏈(CoT)推理為安全和對齊提供了新的思路。OpenAI發現,將模型行為策略整合到推理模型的思維鏈中,可以高效、穩健地教導人類價值觀和原則。通過向模型教導自己的安全規則以及如何在上下文中推理它們,OpenAI發現推理能力直接有利于模型穩健性的證據:o1-preview在關鍵越獄評估和用于評估模型安全拒絕邊界的最嚴格內部基準上取得了顯著的改進。
OpenAI認為,使用思維鏈可以為安全和對齊帶來重大進步,因為1)它能夠以清晰的方式觀察模型思維,并且2)關于安全規則的模型推理對于分布外場景更具穩健性。
為了對自己的改進進行壓力測試,OpenAI在部署之前根據自己的安全準備框架進行了一系列安全測試和紅隊測試。結果發現,思維鏈推理有助于在整個評估過程中提高能力。尤其值得注意的是,OpenAI觀察到了有趣的獎勵黑客攻擊實例。
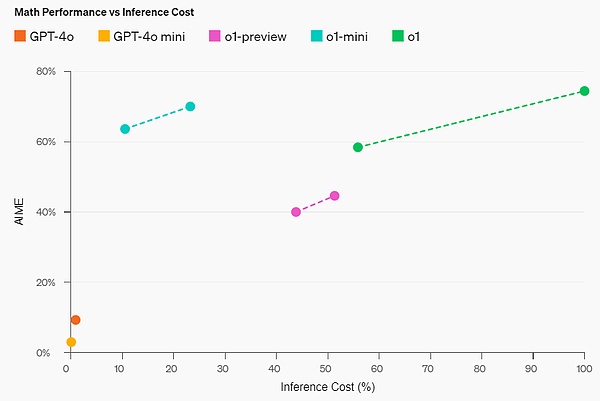
數學能力:在高中AIME數學競賽中,o1-mini(70.0%)與o1(74.4%)不相上下,但價格卻便宜很多,并且優于o1-preview(44.6%)。o1-mini的得分(約11/15個問題)大約位于美國前500名高中生之列。
編碼能力:在Codeforces競賽網站上,o1-mini的Elo得分為1650,與o1(1673)不相上下,并且高于o1-preview(1258)。此外,o1-mini在HumanEval編碼基準和高中網絡安全奪旗挑戰(CTF)中也表現出色。
STEM:在一些需要推理的學術基準上,例如GPQA(科學)和MATH-500,o1-mini的表現優于GPT-4o。o1-mini在MMLU等任務上的表現則不如GPT-4o,并且由于缺乏廣泛的世界知識而在GPQA基準上落后于o1-preview。
人類偏好評估:OpenAI讓人類評分員在各個領域具有挑戰性的開放式提示上比較o1-mini和GPT-4o。與o1-preview類似,在推理密集型領域,o1-mini比GPT-4o更受歡迎;但在以語言為中心的領域,o1-mini并不比GPT-4o更受歡迎。
在速度層面,OpenAI比較了GPT-4o、o1-mini和o1-preview對一個單詞推理問題的回答。結果顯示,GPT-4o回答不正確,而o1-mini和o1-preview均回答正確,并且o1-mini得出答案的速度快了大約3-5倍。
如何使用OpenAIo1?
ChatGPTPlus和Team(個人付費版與團隊版)用戶馬上就可以在該公司的聊天機器人產品ChatGPT中開始使用o1模型了。你可以手動選取使用o1-preview或o1-mini。不過,用戶的使用量有限。
目前,每位用戶每周僅能給o1-preview發送30條消息,給o1-mini發送50條消息。
是的,很少!不過OpenAI表示正在努力提升用戶的可使用次數,并讓ChatGPT能自動針對給定提示詞選擇使用合適的模型。
至于企業版和教育版用戶,要到下周才能開始使用這兩個模型。
至于通過API訪問的用戶,OpenAI表示達到了5級API使用量的開發者可以即刻開始使用這兩個模型開始開發應用原型,但同樣也被限了速:20RPM。什么是5級API使用量?簡單來說,就是已經消費了1000美元以上并且已經是超過1個月的付費用戶。請看下圖:
OpenAI表示對這兩個模型的API調用并不包含函數調用、流式傳輸(streaming)、系統支持消息等功能。同樣,OpenAI表示正在努力提升這些限制。未來
OpenAI表示,未來除了模型更新之外,還將增加網絡瀏覽、文件和圖像上傳等功能,以讓這些模型變得更加有用。
「除了新的o1系列模型,我們計劃繼續開發和發布我們的GPT系列模型。」
參考內容:/p>
https://openai.com/index/introducing-openai-o1-preview/
https://openai.com/index/openai-o1-mini-advancing-cost-efficient-reasoning/
https://openai.com/index/learning-to-reason-with-llms/
https://x.com/sama/status/1834283100639297910