DeepSeek新模型大揭秘:為何它能震動全球AI圈
作者:郝博陽;來源:騰訊科技
本文關注DeepSeek-R1在技術上最重要的突破——用純深度學習的方法讓AI自發涌現出推理能力。這一研究可能會對模型推理訓練后續的范式產生深刻影響。
時隔不到一個月,DeepSeek又一次震動全球AI圈。
去年12月,DeepSeek推出的DeepSeek-V3在全球AI領域掀起了巨大的波瀾,它以極低的訓練成本,實現了與GPT-4o和ClaudeSonnet3.5等頂尖模型相媲美的性能,震驚了業界。
騰訊科技曾對此模型進行深度解讀,用最簡單直白的語言闡釋其實現低成本和高效能的技術背景(點擊可查看)。
和上次不同的是,這次推出的新模型DeepSeek-R1不僅成本低,更是在技術上有了大福提升。
而且,它還是一個開源模型。
這款新模型延續了其高性價比的優勢,僅用十分之一的成本就達到了GPT-o1級別的表現。
所以,很多業內人士甚至喊出了“DeepSeek接班OpenAI”的口號。
比如,前MetaAI工作人員、知名AI論文推特作者Elvis就強調,DeepSeek-R1的論文堪稱瑰寶,因為它探索了提升大語言模型推理能力的多種方法,并發現了其中更明確的涌現特性。
JimFan甚至認為,它們做了OpenAI本來應該做的事,開源。
傳統的模型訓練路徑
但DeepSeek-R1-Zero選擇了一條前所未有的路徑“純”強化學習路徑,它完全拋開了預設的思維鏈模板(ChainofThought)和監督式微調(SFT),僅依靠簡單的獎懲信號來優化模型行為。
這就像讓一個天才兒童在沒有任何范例和指導的情況下,純粹通過不斷嘗試和獲得反饋來學習解題。
DeepSeek-R1-Zero有的只是一套最簡單的獎勵系統,來激發AI的推理能力。
這個規則就兩條:
1. 準確性獎勵:準確性獎勵模型評估響應是否正確。對了就加分,錯了扣分。評價方法也很簡單:例如,在具有確定性結果的數學問題中,模型需要以指定格式(如
2. 格式獎勵:格式獎勵模型強制要求模型將其思考過程置于
為了準確觀察模型在強化學習(RL)過程中的自然進展,DeepSeek甚至有意將系統提示詞僅約束限制在這種結構格式上,來避免任何內容特定的偏見——例如強制讓模型進行反思性推理或推廣特定的問題解決策略。

這種頓悟往往是模型思維能力躍升的時刻。
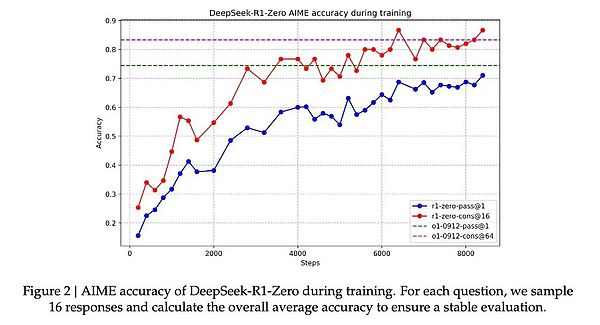
因為根據DeepSeek的研究,模型的進步并非均勻漸進的。在強化學習過程中,響應長度會出現突然的顯著增長,這些"跳躍點"往往伴隨著解題策略的質變。這種模式酷似人類在長期思考后的突然頓悟,暗示著某種深層的認知突破。
最有說服力的或許是模型展現出的遷移學習能力。在完全不同的編程競賽平臺Codeforces上,R1-Zero達到了超過96.3%人類選手的水平。這種跨域表現表明,模型不是在死記硬背特定領域的解題技巧,而是掌握了某種普適的推理能力。一個聰明,但口齒不清的天才
盡管R1-Zero展現出了驚人的推理能力,但研究者們很快發現了一個嚴重的問題:它的思維過程往往難以被人類理解。
論文坦誠地指出,這個純強化學習訓練出來的模型存在"poorreadability"(可讀性差)和"languagemixing"(語言混雜)的問題。
這個現象其實很好理解:R1-Zero完全通過獎懲信號來優化其行為,沒有任何人類示范的"標準答案"作為參考。就像一個天才兒童自創了一套解題方法,雖然屢試不爽,但向別人解釋時卻語無倫次。它在解題過程中可能同時使用多種語言,或者發展出了某種特殊的表達方式,這些都讓其推理過程難以被追蹤和理解。
正是為了解決這個問題,研究團隊開發了改進版本DeepSeek-R1。通過引入更傳統的"cold-startdata"(冷啟動數據)和多階段訓練流程,R1不僅保持了強大的推理能力,還學會了用人類易懂的方式表達思維過程。這就像給那個天才兒童配了一個溝通教練,教會他如何清晰地表達自己的想法。
在這一調教下之后,DeepSeek-R1展現出了與OpenAIo1相當甚至在某些方面更優的性能。在MATH基準測試上,R1達到了77.5%的準確率,與o1的77.3%相近;在更具挑戰性的AIME2024上,R1的準確率達到71.3%,超過了o1的71.0%。在代碼領域,R1在Codeforces評測中達到了2441分的水平,高于96.3%的人類參與者。
然而,DeepSeek-R1Zero的潛力似乎更大。它在AIME2024測試中使用多數投票機制時達到的86.7%準確率——這個成績甚至超過了OpenAI的o1-0912。這種"多次嘗試會變得更準確"的特征,暗示R1-Zero可能掌握了某種基礎的推理框架,而不是簡單地記憶解題模式。
論文數據顯示,從MATH-500到AIME,再到GSM8K,模型表現出穩定的跨域性能,特別是在需要創造性思維的復雜問題上。這種廣譜性能提示R1-Zero可能確實培養出了某種基礎的推理能力,這與傳統的特定任務優化模型形成鮮明對比。
所以,雖然口齒不清,但也許DeepSeek-R1-Zero才是真正理解了推理的“天才”。純粹強化學習,也許才是通向AGI的意外捷徑
之所以DeepSeek-R1的發布讓圈內人的焦點都投向了純強化學習方法,因為它完全可以說得上是打開了AI進化的一條新路徑。
R1-Zero——這個完全通過強化學習訓練出來的AI模型,展現出了令人驚訝的通用推理能力。它不僅在數學競賽中取得了驚人成績。
更重要的是,R1-Zero不僅是在模仿思考,而是真正發展出了某種形式的推理能力。
因為在過往的訓練方法中,尤其在監督微調中使用訓練好的神經網絡來評估質量的話,模型可能學會觸發獎勵模型的特定模式,生成對獎勵模型"口味"的內容,而不是真正提升推理能力。換句話說,AI系統找到了獲得高獎勵但實際上違背訓練目標的投機取巧方式。這就是我們常說的獎勵欺騙(rewardhacking)。但R1-Zero用極簡的獎勵規則基本避免了獎勵欺騙的可能性——規則太簡單了,沒有什么“口味”可以去模仿。模型在這個情況下發展出的推理能力更可信,也更自然。
這個發現可能會改變我們對機器學習的認識:傳統的AI訓練方法可能一直在重復一個根本性的錯誤,我們太專注于讓AI模仿人類的思維方式了,業界需要重新思考監督學習在AI發展中的角色。通過純粹的強化學習,AI系統似乎能夠發展出更原生的問題解決能力,而不是被限制在預設的解決方案框架內。
雖然R1-Zero在輸出可讀性上存在明顯缺陷,但這個"缺陷"本身可能恰恰印證了其思維方式的獨特性。就像一個天才兒童發明了自己的解題方法,卻難以用常規語言解釋一樣。這提示我們:真正的通用人工智能可能需要完全不同于人類的認知方式。
這才是真正的強化學習。就像著名教育家皮亞杰的理論:真正的理解來自于主動建構,而不是被動接受。