一文讀懂英偉達GTC:有關Blackwell全家桶、硅光芯片和黃仁勛的“新故事”
作者:蘇揚、郝博陽;來源:騰訊科技
作為AI時代的“賣鏟人”,黃仁勛和他的英偉達,始終堅信算力永不眠。
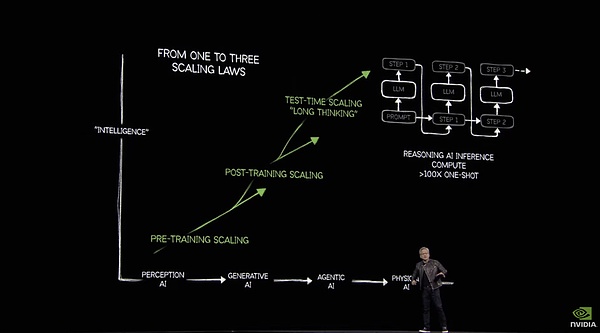
黃仁勛在GTC演講中稱推理讓算力需求暴增100倍
今天的GTC大會上,黃仁勛拿出了全新的BlackwellUltraGPU,以及在此基礎上衍生的應用于推理、Agent的服務器SKU,也包括基于Blackwell架構的RTX全家桶,這一切都與算力有關,但接下來更重要的是,如何將源源不斷算力,合理有效地消耗掉。
在黃仁勛眼里,通往AGI需要算力,具身智能機器人需要算力,構建Omniverse與世界模型更需要源源不斷的算力,至于最終人類構建一個虛擬的“平行宇宙”,需要多少算力,英偉達給了一個答案——過去的100倍。
為了支撐自己的觀點,黃仁勛在GTC現場曬了一組數據——2024年美國前四云廠總計采購130萬顆Hopper架構芯片,到了2025年,這一數據飆升至360萬顆BlackwellGPU。
以下是騰訊科技整理的英偉達GTC2025大會的一些核心要點:Blackwell全家桶上線1)年度“核彈”BlackwellUltra在擠牙膏
英偉達去年GTC發布Blackwell架構,并推出GB200芯片,今年的正式名稱做了微調,不叫之前傳言的GB300,直接就稱之為BlakwellUltra。
但從硬件來看,就是在去年基礎上更換了新的HBM內存。一句話理解就是,BlackwellUltra=Blackwell大內存版本。
BlackwellUltra由兩顆臺積電N4P(5nm)工藝,Blackwell架構芯片+GraceCPU封裝而來,并且搭配了更先進的12層堆疊的HBM3e內存,顯存提升至為288GB,和上一代一樣支持第五代NVLink,可實現1.8TB/s的片間互聯帶寬。

NVLink歷代性能參數
基于存儲的升級,BlackwellGPU的FP4精度算力可以達到15PetaFLOPS,基于AttentionAcceleration機制的推理速度,比Hopper架構芯片提升2.5倍。2)BlackwellUltraNVL72:AI推理專用機柜

BlackwellUltraNVL72官方圖
和GB200NVL72一樣,英偉達今年也推出了類似的產品BlackwellUltraNVL72機柜,一共由18個計算托盤構成,每個計算托盤包含4顆BlackwellUltraGPU+2顆GraceCPU,總計也就是72顆BlackwellUltraGPU+36顆GraceCPU,顯存達到20TB,總帶寬576TB/s,外加9個NVLink交換機托盤(18顆NVLink交換機芯片),節點間NVLink帶寬130TB/s。
機柜內置72張CX-8網卡,提供14.4TB/s帶寬,Quantum-X800InfiniBand和Spectrum-X800G以太網卡則可以降低延遲和抖動,支持大規模AI集群。此外,機架還整合了18張用于增強多租戶網絡、安全性和數據加速BlueField-3DPU。
英偉達說這款產品是“為AI推理時代”專門定制,應用場景包括推理型AI、Agent以及物理AI(用于機器人、智駕訓練用的數據仿真合成),相比前一代產品GB200NVL72的AI性能提升了1.5倍,而相比Hopper架構同定位的DGX機柜產品,可以為數據中心提供50倍增收的機會。
根據官方提供的信息,6710億參數DeepSeek-R1的推理,基于H100產品可實現每秒100tokens,而采用BlackwellUltraNVL72方案,可以達到每秒1000tokens。
換算成時間,同樣的推理任務,H100需要跑1.5分鐘,而BlackwellUltraNVL7215秒即可跑完。
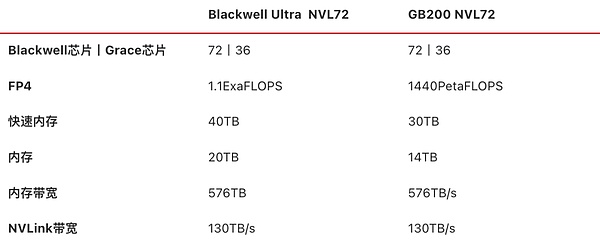
BlackwellUltraNVL72和GB200NVL72硬件參數
根據英偉達提供的信息,BlackwellNVL72相關產品預計在2025年下半年上市,客戶包括服務器廠商、云廠、算力租賃服務商幾大類:
服務器廠商
Cisco/Dell/HPE/Lenovo/超微等15家制造商
云廠
AWS/GoogleCloud/Azure/Oracle云等主流平臺
算力租賃服務商
CoreWeave/Lambda/Yotta等3)提前預告真“核彈”GPURubin芯片
按照英偉達的路線圖,GTC2025的主場就是BlackwellUltra。
不過,黃仁勛也借這個場子預告了2026年上市的基于Rubin架構的下一代GPU以及更強的機柜VeraRubinNVL144——72顆VeraCPU+144顆RubinGPU,采用288GB顯存的HBM4芯片,顯存帶寬13TB/s,搭配第六代NVLink和CX9網卡。
這個產品有多強呢?FP4精度的推理算力達到了3.6ExaFLOPS,FP8精度的訓練算力也達到了1.2ExaFlOPS,性能是BlackwellUltraNVL72的3.3倍。
如果你覺得還不夠,沒關系,2027年還有更強的RubinUltraNVL576機柜,FP4精度的推理和FP8精度的訓練算力分別是15ExaFLOPS和5ExaFLOPS,14倍于BlackwellUltraNVL72。

4)BlackwellUltra版DGXSuperPOD“超算工廠“
對于那些現階段BlackwellUltraNVL72都不能滿足需求,又不需要搭建超大規模AI集群的客戶,英偉達的解決方案是基于BlackwellUltra、即插即用的DGXSuperPODAI超算工廠。
作為一個即插即用的AI超算工廠,DGXSuperPOD主要面向專為生成式AI、AIAgent和物理模擬等AI場景,覆蓋從預訓練、后訓練到生產環境的全流程算力擴展需求,Equinix作為首個服務商,提供液冷/風冷基礎架構支持。

由BlackwellUltra構建的DGXSuperPod
基于BlackwellUltra定制的DGXSuperPOD分兩個版本:
內置DGXGB300(GraceCPU×1+BlackwellUltraGPU×2) 的DGXSuperPOD,總計288顆GraceCPU+576顆BlackwellUltraGPU,提供300TB的快速內存,FP4精度下算力為11.5ExaFLOPS
內置DGXB300的DGXSuperPOD,這個版本不含GraceCPU芯片,具備進一步的擴展空間,且采用的是風冷系統,主要應用場景為普通的企業級數據中心5)DGXSpark與DGXStation
今年1月份,英偉達在CES上曬了一款售價3000美元的概念性的AIPC產品——ProjectDIGITS,現在它有了正式名稱DGXSpark。
產品參數方面,搭載GB10芯片,FP4精度下算力可以達到1PetaFlops,內置128GBLPDDR5X內存,CX-7網卡,4TBNVMe存儲,運行基于Linux定制的DGXOS操作系統,支持Pytorch等框架,且預裝了英偉達提供的一些基礎AI軟件開發工具,可以運行2000億參數模型。整機的尺寸和Macmini的大小接近,兩臺DGXSpark互聯,還可以運行超過4000億參數的模型。
雖然我們說它是AIPC,但本質上仍然屬于超算范疇,所以被放在了DGX產品系列當中,而不是RTX這樣的消費級產品里面。
不過也有人吐槽這款產品,FP4的宣傳性能可用性低,換算到FP16精度下只能跟RTX5070,甚至是250美元的ArcB580對標,因此性價比極低。

DGXSpark計算機與DGXStation工作站
除了擁有正式名稱的DGXSpark,英偉達還推出了一款基于BlackwellUltra的AI工作站,這個工作站內置一顆GraceCPU和一顆BlackwellUltraGPU,搭配784GB的統一內存、CX-8網卡,提供20PetaFlops的AI算力(官方未標記,理論上也是FP4精度)。6)RTX橫掃AIPC,還要擠進數據中心
前面介紹的都是基于GraceCPU和BlackwellUltraGPU的產品SKU,且都是企業級產品,考慮到很多人對RTX4090這類產品在AI推理上的妙用,英偉達本次GTC也進一步強化了Blackwell和RTX系列的整合,推出了一大波內置GDDR7內存的AIPC相關GPU,覆蓋筆記本、桌面甚至是數據中心等場景。
桌面GPU:,包括RTXPRO6000Blackwell工作站版、RTXPRO6000BlackwellMax-Q工作站版、RTXPRO5000Blackwell、RTXPRO4500Blackwell以及RTXPRO4000Blackwell
筆記本GPU:RTXPRO5000Blackwell、RTXPRO4000Blackwell、RTX、PRO3000Blackwell、RTXPRO2000Blackwell、RTXPRO1000Blackwell以及RTXPRO500Blackwell
數據中心GPU:NVIDIARTXPRO6000Blackwell服務器版

英偉達針對企業級計算打造的AI“全家桶”
以上還只是部分基于BlackwellUltra芯片針對不同場景定制的SKU,小到工作站,大到數據中心集群,英偉達自己將其稱之為“BlackwellFamily”(Blackwell家族),中文翻譯過來“Blackwell全家桶”再合適不過。英偉達Photonics:站在隊友肩膀上的CPO系統
光電共封模塊(CPO)的概念,簡單來說就是將交換機芯片和光學模塊共同封裝,可實現光信號轉化為電信號,充分利用光信號的傳輸性能。
在此之前,業界就一直在討論英偉達的CPO網絡交換機產品,但一直遲遲未上線,黃仁勛在現場也給了解釋——由于在數據中心中大量使用光纖連接,光學網絡的功耗相當于計算資源的10%,光連接的成本直接影響著計算節點的Scale-Out網絡和AI性能密度提升。

GTC上展示的兩款硅光共封芯片Quantum-X、Spectrum-X參數
今年的GTC英偉達一次性推出了Quantum-X硅光共封芯片、Spectrum-X硅光共封芯片以及衍生出來的三款交換機產品:Quantum3450-LD、SpectrumSN6810和SpectrumSN6800。
Quantum3450-LD:144個800GB/s端口,背板帶寬115TB/s,液冷
SpectrumSN6810:128個800GB/s端口,背板帶寬102.4TB/s,液冷
SpectrumSN6800:512個800GB/s端口,背板帶寬409.6TB/s,液冷
上述產品統一歸類到“NVIDIAPhotonics”,英偉達說這是一個基于CPO合作伙伴生態共創研發的平臺,例如其搭載的微環調制器(MRM)是基于臺積電的光引擎優化而來,支持高功率、高能效激光調制,并且采用可拆卸光纖連接器。
比較有意思的是,根據之前業內的資料,臺積電的微環調制器(MRM)是其與博通基于3nm工藝以及CoWoS等先進封裝技術打造而來。
按照英偉達給的數據,整合光模塊的Photonics交換機相比傳統交換機,性能提升3.5倍,部署效率也可以提升1.3倍,以及10倍以上的擴展彈性。模型效率PKDeepSeek:軟件生態發力AIAgent

黃仁勛在現場描繪AIinfra的“大餅”
因為本次長達2個小時的GTC上,黃仁勛總共只講大概半個小時軟件和具身智能。因此很多細節都是通過官方文檔進行補充的,而非完全來自現場。1)NvidiaDynamo,英偉達在推理領域構建的新CUDA
NvidiaDynamo絕對是本場發布的軟件王炸。
它是一個專為推理、訓練和跨整個數據中心加速而構建的開源軟件。Dynamo的性能數據相當震撼:在現有Hopper架構上,Dynamo可讓標準Llama模型性能翻倍。而對于DeepSeek等專門的推理模型,NVIDIADynamo的智能推理優化還能將每個GPU生成的token數量提升30倍以上。
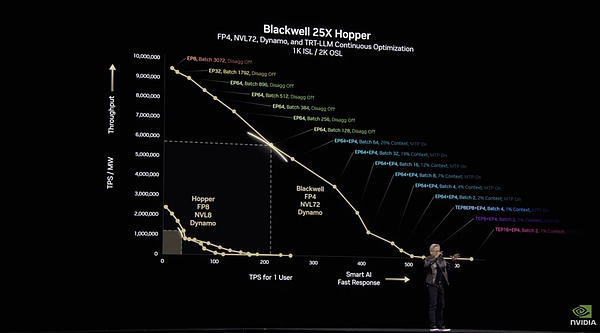
黃仁勛演示加了Dynamo的Blackwell能超過25倍的Hopper
Dynamo的這些改進主要得益于分布化。它將LLM的不同計算階段(理解用戶查詢和生成最佳響應)分配到不同GPU,使每個階段都能獨立優化,提高吞吐量并加快響應速度。
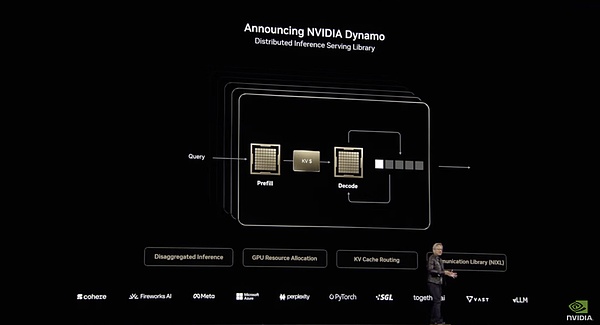
Dynamo的系統架構
比如在輸入處理階段,也就是預填充階段,Dynamo能夠高效地分配GPU資源來處理用戶輸入。系統會利用多組GPU并行處理用戶查詢,希望GPU處理的更分散、更快。Dynamo用FP4模式調用多個GPU同時并行“閱讀”和“理解”用戶的問題,其中一組GPU處理“第二次世界大戰”的背景知識、另一組處理“起因“相關的歷史資料、第三組處理“經過“的時間線和事件,這一階段像是多個研究助理同時查閱大量資料。
而在生成輸出tokens,也就是解碼階段,則需要讓GPU更專注和連貫。比起GPU數量,這個階段更需要更大的帶寬去吸取前一階段的思考信息,因此也需要更多的緩存讀取。Dynamo優化了GPU間通信和資源分配,確保連貫且高效的響應生成。它一方面充分利用了NVL72架構的高帶寬NVLink通信能力,最大化令牌生成效率。另一方面通過“SmartRouter”將請求定向到已緩存相關KV(鍵值)的GPU上,這可以避免重復計算,極大地提高了處理速度。由于避免了重復計算,一些GPU資源被釋放出來Dynamo可以將這些空閑資源動態分配給新的傳入請求。
這一套架構和Kimi的Mooncake架構非常類似,但在底層infra上英偉達做了更多支持。Mooncake大概可以提升5倍左右,但Dynamo在推理上提升的更明顯。
比如Dynamo的幾項重要創新中,“GPUPlanner”能夠根據負載動態調整GPU分配,“低延遲通信庫”優化了GPU間數據傳輸,而“內存管理器”則智能地將推理數據在不同成本級別的存儲設備間移動,進一步降低運營成本。而智能路由器,LLM感知型路由系統,將請求定向到最合適的GPU,減少重復計算。這一系列能力都使得GPU的負載達到最佳化。
利用這一套軟件推理系統能夠高效擴展到大型GPU集群,最高可以使單個AI查詢無縫擴展到多達1000個GPU,以充分利用數據中心資源。
而對于GPU運營商來講,這個改進使得每百萬令牌成本顯著下降,而產能大幅提升。同時單用戶每秒獲得更多token,響應更快,用戶體驗改善。
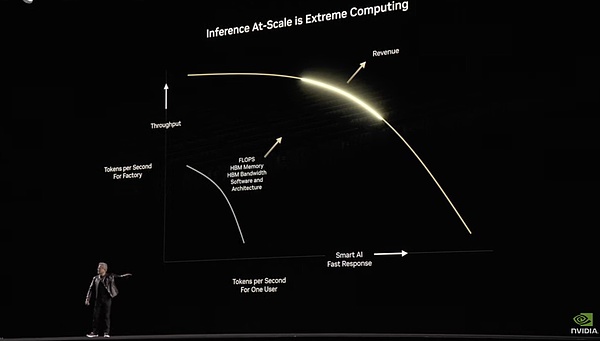
用Dynamo,讓服務器達到吞吐量和應答速度間的黃金收益線
與CUDA作為GPU編程的底層基礎不同,Dynamo是一個更高層次的系統,專注于大規模推理負載的智能分配和管理。它負責推理優化的分布式調度層,位于應用程序和底層計算基礎設施之間。但就像CUDA十多年前徹底改變了GPU計算格局,Dynamo也可能成功開創推理軟硬件效率的新范式。
Dynamo完全開源,支持從PyTorch到TensorRT的所有主流框架。開源了也照樣是護城河。和CUDA一樣,它只對英偉達的GPU有效果,是NVIDIAAI推理軟件堆棧的一部分。
用這個軟件升級,NVIDIA構筑了自己反擊Groq等專用推理AISC芯片的城防。必須軟硬搭配,才能主導推理基礎設施。2)LlamaNemotron新模型秀高效,但還是打不過DeepSeek
雖然在服務器利用方面,Dynamo確實相當驚艷,但在訓練模型方面英偉達還和真內行有點差距。
英偉達在這次GTC上用一款新模型LlamaNemotron,主打高效、準確。它是由Llama系列模型衍生而來。經過英偉達特別微調,相較于Llama本體,這款模型經過算法修剪優化,更加輕量級,僅有48B。它還具有了類似o1的推理能力。與Claude3.7和Grok3一樣,LlamaNemotron模型內置了推理能力開關,用戶可選擇是否開啟。這個系列分為三檔:入門級的Nano、中端的Super和旗艦Ultra,每一款都針對不同規模的企業需求。
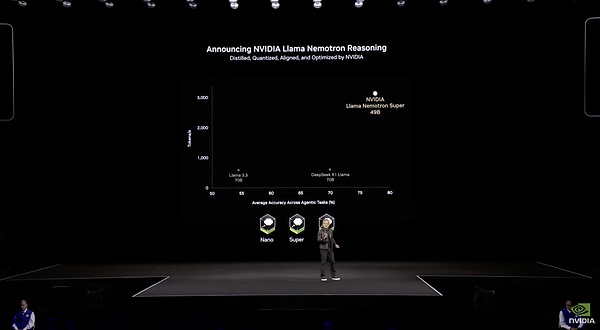
LlamaNemotron的具體數據
說到高效,這一模型的微調數據集完全英偉達自己生成的合成數據組成,總數約60Btoken。相比DeepSeekV3用130萬H100小時完整訓練,這個僅有DeepSeekV31/15參數量的模型只是微調就用了36萬H100小時。訓練效率比DeepSeek差一個等級。
在推理上效率上,LlamaNemotronSuper49B模型確實比上一代模型表現要好得多,其token吞吐量能達到Llama370B的5倍,在單個數據中心GPU下它可以每秒吞吐3000token以上。但在DeepSeek開源日最后一天公布的數據中,每個H800節點在預填充期間平均吞吐量約為73.7ktokens/s輸入(包括緩存命中)或在解碼期間約為14.8ktokens/s輸出。兩者差距還是很明顯的。
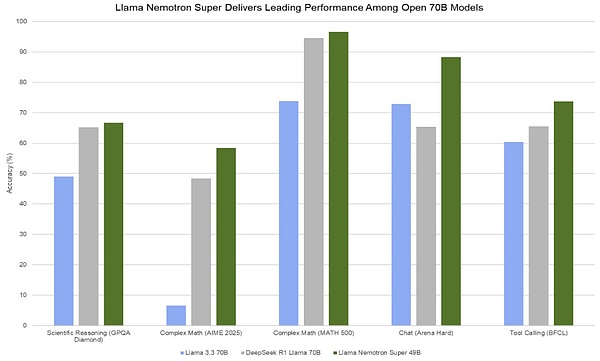
DeepSeekR1蒸餾過的Llama70B模型。不過考慮到最近QwenQwQ32B模型之類的小參數高能模型頻繁發布,LlamaNemotronSuper估計在這些能和R1本體掰手腕的模型里難以出彩。
最要命的是,這個模型,等于實錘了DeepSeek也許比英偉達更懂在訓練過程中調教GPU。3)新模型只是英偉達AIAgent生態的前菜,NVIDAAIQ才是正餐
英偉達為什么要開發一個推理模型呢?這主要是為了老黃看中的AI下一個爆點——AIAgent做準備。自從OpenAI、Claude等大廠逐步通過DeepReasearch、MCP建立起了Agent的基礎后,英偉達明顯也認為Agent時代到來了。
NVIDAAIQ項目就是英偉達的嘗試。它直接提供了一個以LlamaNemotron推理模型為核心的規劃者的AIAgent現成工作流。這一項目歸屬于英偉達的Blueprint(藍圖)層級,它是指一套預配置的參考工作流、是一個個模版模板,幫助開發者更容易地整合NVIDIA的技術和庫。而AIQ就是英偉達提供的Agent模版。
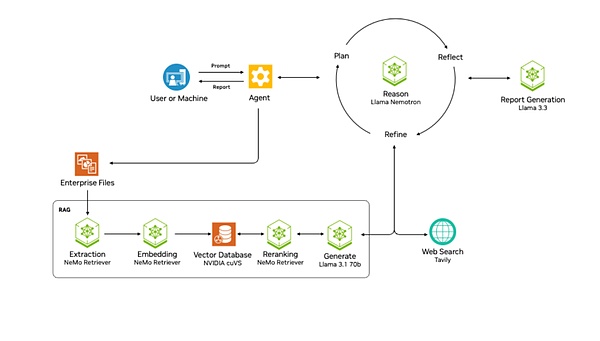
NVIDAAIQ的架構
和Manus一樣,它集成網絡搜索引擎及其他專業AI代理等外部工具,這讓這個Agent本身可以既能搜索,又能使用各種工具。通過LlamaNemotron推理模型的規劃,反思和優化處理方案,去完成用戶的任務。除此之外,它還支持多Agent的工作流架構搭建。
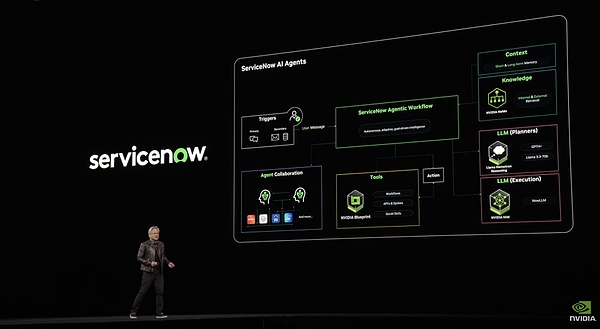
基于這套模版做的servicenow系統
比Manus更進一步的是,它具有一個復雜的針對企業文件的RAG系統。這一系統包括提取、嵌入、向量存儲、重排到最終通過LLM處理的一系列步驟,能保證企業數據為Agent所用。
在此之上,英偉達還推出了AI數據平臺,把AI推理模型接到企業數據的系統上,形成一個針對企業數據的DeepReasearch。使得存儲技術的重大演進,使得存儲系統不再僅是數據的倉庫,而是擁有主動推理和分析能力的智能平臺。
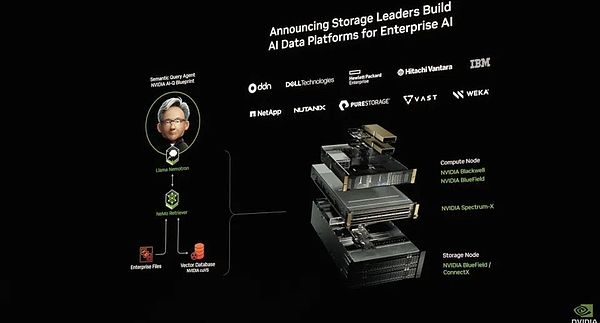
AIDataPlatform的構成
另外,AIQ非常強調可觀察性和透明度機制。這對于安全和后續改進來講非常重要。開發團隊能夠實時監控Agent的活動,并基于性能數據持續優化系統。
整體來講NVIDAAIQ是個標準的Agent工作流模版,提供了各種Agent能力。算是進化到推理時代的,更傻瓜的Dify類Agent構筑軟件。人形機器人基礎模型發布英偉達要做具身生態全閉環1)Cosmos,讓具身智能理解世界
如果說專注Agent還是投注現在,那英偉達在具身智能上的布局完全算得上是整合未來了。
模型、數據、算力這模型三要素英偉達都給安排齊了。
先從模型開始說,本次GTC放出了今年1月公布的具身智能基礎模型Cosmos的升級版。
Cosmos是一個能通過現在畫面,去預測未來畫面的模型。它可以從文本/圖像輸入數據,生成詳細的視頻,并通過將其的當前狀態(圖像/視頻)與動作(提示/控制信號)相結合來預測場景的演變。因為這需要對世界的物理因果規律有理解,所以英偉達稱Cosmos是世界基礎模型(WFM)。
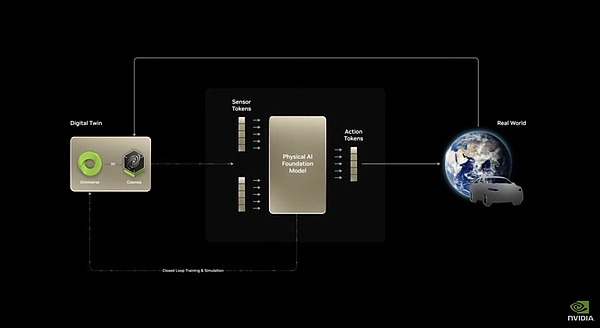
Cosmos的基本架構
而對于具身智能而言,預測機器的行為會給外部世界帶來什么影響是最核心的能力。只有這樣,模型才能去根據預測規劃行為,所以世界模型就成了具身智能的基礎模型。有了這個基礎的行為/時間-物理世界改變的世界預測模型,通過具體的如自動駕駛、機器人任務的數據集微調,這個模型就可以滿足各種具有物理形態的具身智能的實際落地需要了。
整個模型包含三部分能力,第一部分CosmosTransfer將結構化的視頻文字輸入轉換為可控的真實感視頻輸出,憑空用文字產生大規模合成數據。這解決了當前具身智能最大的瓶頸——數據不足問題。而且這種生成是一種“可控”生成,這意味著用戶可以指定特定參數(如天氣條件、物體屬性等),模型會相應調整生成結果,使數據生成過程更加可控和有針對性。整個流程還可以由Ominiverse和Cosmos結合。

Cosmos建立在Ominiverse上的現實模擬
第二部分CosmosPredict能夠從多模態輸入生成虛擬世界狀態,支持多幀生成和動作軌跡預測。這意味著,給定起始和結束狀態,模型可以生成合理的中間過程。這是核心物理世界認知和構建能力。
第三部分是CosmosReason,它是個開放且可完全定制的模型,具有時空感知能力,通過思維鏈推理理解視頻數據并預測交互結果。這是規劃行為和預測行為結果的提升能力。
有了這三部分能力逐步疊加,Cosmos就可以做到從現實圖像token+文字命令提示token輸入到機器動作token輸出的完整行為鏈路。
這一基礎模型應該確實效果不俗。推出僅兩個月,1X、AgilityRobotics、FigureAI這三家頭部公司都開始用起來了。大語言模型沒領先,但具身智能英偉達確實在第一梯隊里。2)IsaacGR00TN1,世界第一個人形機器人基礎模型
有了Cosmos,英偉達自然而然用這套框架微調訓練了專用于人型機器人的基礎模型IsaacGR00TN1。
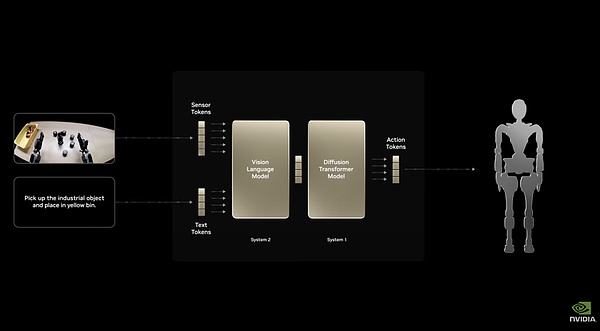
IsaacGR00TN1的雙系統架構
它采用雙系統架構,有快速反應的“系統1“和深度推理的“系統2“。它的全面微調,使得其能處理抓取、移動、雙臂操作等通用任務。而且可以根據具體機器人進行完全定制,機器人開發者可用真實或合成數據進行后訓練。這使得這一模型實際上可以被部署在各種各樣形狀各異的機器人中。
比如說英偉達與GoogleDeepMind和迪士尼合作開發Newton物理引擎,就用了IsaacGR00TN1作為底座驅動了一個非常不常見的小迪士尼BDX機器人。可見其通用性之強。Newton作為物理引擎非常細膩,因此足夠建立物理獎勵系統,以在虛擬環境中訓練具身智能。

黃仁勛與BDX機器人臺上“激情”互動4)數據生成,雙管齊下
英偉達結合NVIDIAOmniverse和上面提到的NVIDIACosmosTransfer世界基礎模型,做出了IsaacGR00TBlueprint。它能從少量人類演示中生成大量合成動作數據,用于機器人操作訓練。NVIDIA使用Blueprint的首批組件,在僅11小時內生成了78萬個合成軌跡,相當于6,500小時(約9個月)的人類演示數據。IsaacGR00TN1的相當一部分數據就來自于此,這些數據使得GR00TN1的性能比僅使用真實數據提高了40%。

孿生模擬系統
針對每個模型,靠著Omniverse這套純虛擬系統,以及CosmosTransfer這套真實世界圖像生成系統,英偉達都能提供大量的高質量數據。這模型的第二個方面,英偉達也覆蓋了。3)三位一體算力體系,打造從訓練到端的機器人計算帝國
從去年開始,老黃就在GTC上強調一個「三臺計算機」的概念:一臺是DGX,就是大型GPU的服務器,它用來訓練AI,包括具身智能。另一臺AGX,是NVIDIA為邊緣計算和自主系統設計的嵌入式計算平臺,它用來具體在端側部署AI,比如作為自動駕駛或機器人的核心芯片。第三臺就是數據生成計算機Omniverse+Cosmos。
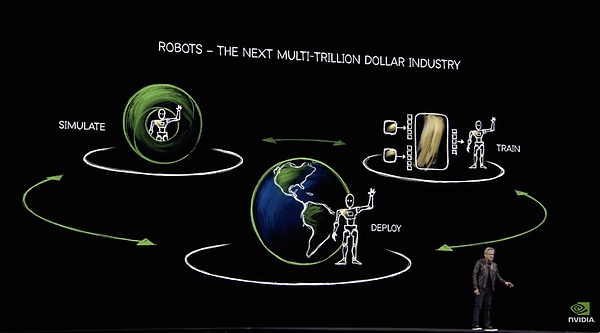
具身智能的三大計算體系
這套體系在本次GTC中又被老黃重提,且特別提到靠著這套算力系統,能誕生十億級的機器人。從訓練到部署,算力都用英偉達。這一部分也閉環了。結語
如果單純對比上一代Blackwell芯片,BlackwellUltra在硬件上確實匹配不上之前的“核彈”、“王炸”這些形容詞,甚至有些擠牙膏的味道。
但如果從路線圖規劃的角度來看,這些又都在黃仁勛的布局之中,明年、后年的Rubin架構,從芯片工藝,到晶體管,再到機架的集成度,GPU互聯和機柜互聯等規格都會有大幅度提升,用中國人習慣說的叫“好戲還在后頭”。
對比硬件層面上的畫餅充饑,這兩年英偉達在軟件層面上可以說是狂飆突進。
縱觀英偉達的整個軟件生態,Meno、Nim、Blueprint三個層級的服務把模型優化、模型封裝到應用構建的全棧解決方案都包括進去了。云服務公司的生態位英偉達AI全部重合。加上這次新增的Agent,AIinfra這塊餅,英偉達是除了基礎模型這一塊之外,所有部分都要吃進去。
軟件這部分,老黃的胃口,和英偉達的股價一樣大。
而在機器人市場,英偉達的野心更大。模型,數據,算力三要素都抓在手里。沒趕上基礎語言模型的頭把交椅,基礎具身智能補齊。影影綽綽,一個具身智能版的壟斷巨頭已經在地平線上露頭了。
這里面,每個環節,每個產品都對應著一個潛在的千億級市場。早年孤注一擲的好運賭王黃仁勛,靠著GPU壟斷得來的錢,開始做一場更大的賭局。
如果這場賭局里,軟件或者機器人市場任意一方面通吃,那英偉達就是AI時代的谷歌,食物鏈上的頂級壟斷者。
不過看看英偉達GPU的利潤率,我們還是期待這樣的未來別來了。
還好,這對于老黃這輩子來講,也是他從沒操盤過的大賭局,勝負難料。