蘋果新論文分析DeepSeek-R1遇到復(fù)雜度閾值后準(zhǔn)確率崩潰問(wèn)題
相信使用過(guò)DeepSeek-R1模型的人,對(duì)于它在給出答案之前的思考過(guò)程并不陌生,這也是包含DeepSeek-R1在內(nèi)的大型推理模型(LRM,LargeReasoningModel)備受推崇的原因之一。
然而,由蘋果公司六位研究人員組成的團(tuán)隊(duì)卻對(duì)此提出了質(zhì)疑。通過(guò)讓模型解答各種謎題,研究團(tuán)隊(duì)發(fā)現(xiàn)DeepSeek-R1、o3-mini和Claude-3.7-Sonnet-Thinking這幾款前沿大型推理模型在超過(guò)某一復(fù)雜度閾值之后,它們的準(zhǔn)確率會(huì)出現(xiàn)全面崩潰。

圖|相關(guān)論文的六位作者,右二為薩米·本吉奧(SamyBengio)(來(lái)源:資料圖)
X上有一名網(wǎng)友總結(jié)稱,蘋果這是當(dāng)了一次加里·馬庫(kù)斯(GaryMarcus),其實(shí)加里·馬庫(kù)斯本人也在領(lǐng)英發(fā)帖肯定了蘋果這篇論文。他寫道:“蘋果公司最新發(fā)表的關(guān)于大語(yǔ)言模型中‘推理’能力的論文頗具震撼力。我在一篇周末長(zhǎng)文中解釋了其中的原因(并探討了一種可能的反對(duì)意見(jiàn)),以說(shuō)明為何大家其實(shí)不應(yīng)感到太過(guò)驚訝。”
在加里·馬庫(kù)斯的“周末長(zhǎng)文”里他寫道:“這篇蘋果公司的新論文進(jìn)一步佐證了我本人的批評(píng)觀點(diǎn):即便最新研發(fā)的所謂‘推理模型’已經(jīng)迭代超越o1版本,但在漢諾塔等經(jīng)典問(wèn)題上,它們依然無(wú)法實(shí)現(xiàn)分布外可靠推理。對(duì)于那些寄希望于‘推理能力’或‘推理時(shí)計(jì)算’能讓大語(yǔ)言模型重回正軌、擺脫單純規(guī)模擴(kuò)張卻屢屢失敗(始終無(wú)法產(chǎn)出配得上‘GPT-5’名號(hào)的技術(shù)突破)的研究者而言,這無(wú)疑是個(gè)壞消息。”
(來(lái)源:資料圖)
這些謎題具有以下特點(diǎn):
(1)能夠提供對(duì)于復(fù)雜度的精細(xì)控制;
(2)避免現(xiàn)有基準(zhǔn)中常見(jiàn)的污染;
(3)僅需依賴明確給定的規(guī)則,強(qiáng)調(diào)算法化推理能力;
(4)支持基于模擬器的嚴(yán)格評(píng)估,能夠?qū)崿F(xiàn)精確的解決方案檢查和詳細(xì)的故障分析。
通過(guò)實(shí)證研究,他們揭示了關(guān)于當(dāng)前大型推理模型的幾個(gè)關(guān)鍵發(fā)現(xiàn):
首先,盡管大型推理模型通過(guò)強(qiáng)化學(xué)習(xí)能夠?qū)W習(xí)復(fù)雜的自我反思機(jī)制,但它們未能為規(guī)劃任務(wù)開(kāi)發(fā)出可泛化的問(wèn)題解決能力,在超過(guò)一定的復(fù)雜度閾值后,性能會(huì)降至零。
其次,研究團(tuán)隊(duì)在等效推理計(jì)算下對(duì)大型推理模型和標(biāo)準(zhǔn)大模型的比較揭示了三種不同的推理機(jī)制。
第一種機(jī)制是:對(duì)于更簡(jiǎn)單、組合性較低的問(wèn)題,標(biāo)準(zhǔn)大模型表現(xiàn)出更高的效率和準(zhǔn)確性。
第二種機(jī)制是:隨著問(wèn)題復(fù)雜度的適度增加,大型推理模型獲得了優(yōu)勢(shì)。
第三種機(jī)制是:當(dāng)問(wèn)題隨著組合深度的增加而變得復(fù)雜時(shí),兩類模型都經(jīng)歷了徹頭徹尾的性能崩潰。
(來(lái)源:資料圖)
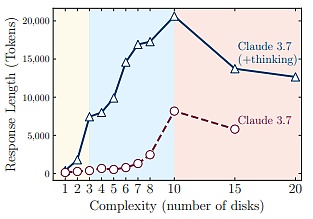
這表明,大型推理模型的推理能力存在一個(gè)根本性限制:其推理時(shí)間會(huì)隨著問(wèn)題復(fù)雜度的增長(zhǎng)而顯著增加。
此外,通過(guò)對(duì)中間推理軌跡的分析,研究團(tuán)隊(duì)發(fā)現(xiàn)了與問(wèn)題復(fù)雜度相關(guān)的規(guī)律性現(xiàn)象,即在較簡(jiǎn)單的問(wèn)題中,推理模型往往能快速找到錯(cuò)誤解,但卻仍會(huì)低效地繼續(xù)探索錯(cuò)誤選項(xiàng),這種現(xiàn)象便是人們常說(shuō)的“過(guò)度思考”。
在中等復(fù)雜度的問(wèn)題中,模型需要經(jīng)過(guò)對(duì)大量錯(cuò)誤路徑的廣泛探索后,才能找到正確解。而超過(guò)一定的復(fù)雜度閾值,模型完全無(wú)法找到正確解。
北京郵電大學(xué)副教授白婷告訴DeepTech,跟人類思維方式相近,對(duì)于復(fù)雜問(wèn)題,雖然不知道什么是正確的答案,但是很多時(shí)候知道什么是不正確的。具體而言,這跟求解空間大小有關(guān)系,簡(jiǎn)單問(wèn)題的求解空間因邏輯鏈條簡(jiǎn)短、特征匹配度高,正確解往往天然處于思維路徑的前端,而復(fù)雜問(wèn)題的解空間因涉及多維度變量耦合、邏輯層級(jí)嵌套而呈現(xiàn)指數(shù)級(jí)膨脹,求解空間龐大,客觀上表現(xiàn)為思維序列中的相對(duì)后置性。推理模型的“思維”內(nèi)部發(fā)生了什么?
研究中,大多數(shù)實(shí)驗(yàn)都是在推理模型及對(duì)應(yīng)的非推理模型上進(jìn)行的,例如Claude3.7Sonnet(有推理/無(wú)推理)和DeepSeek-R1/V3。研究團(tuán)隊(duì)選擇這些模型是因?yàn)榕cOpenAI的o系列等模型不同的是,它們?cè)试S訪問(wèn)思維token。
對(duì)于每個(gè)謎題實(shí)例,研究團(tuán)隊(duì)生成25個(gè)樣本,并報(bào)告了每個(gè)模型的平均性能。
為了更深入地了解推理模型的思考過(guò)程,研究團(tuán)隊(duì)對(duì)它們的推理痕跡進(jìn)行了細(xì)致的分析。
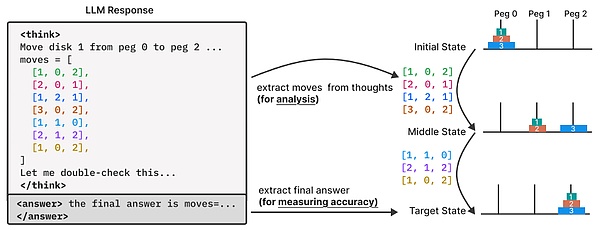
期間,他們通過(guò)謎題實(shí)驗(yàn)環(huán)境的構(gòu)建,實(shí)現(xiàn)了對(duì)模型最終答案之外的深度解析,從而能夠?qū)ζ渖傻耐评碥壽E(即“思考過(guò)程”)進(jìn)行更精細(xì)的觀測(cè)與分析。
具體來(lái)說(shuō),他們借助謎題模擬器,對(duì)模型思維過(guò)程中探索的中間解進(jìn)行了提取與分析。
隨后,他們考察了這些中解的模式和特征、相對(duì)于推理過(guò)程中順序位置的正確性,以及這些模式如何隨著問(wèn)題復(fù)雜度的增加而演變。
對(duì)于這一分析,研究團(tuán)隊(duì)重點(diǎn)關(guān)注了Claude3.7Sonnet推理模型在謎題組實(shí)驗(yàn)中產(chǎn)生的推理痕跡。
對(duì)于痕跡中確定的每個(gè)中間解法,研究團(tuán)隊(duì)記錄了以下內(nèi)容:(1)其在推理軌跡中的相對(duì)位置(按總思維長(zhǎng)度歸一化),(2)經(jīng)研究團(tuán)隊(duì)的謎題模擬器驗(yàn)證的其正確性,(3)相應(yīng)問(wèn)題的復(fù)雜度。
這使得研究團(tuán)隊(duì)能夠描述整個(gè)推理過(guò)程中解決方案形成的進(jìn)展和準(zhǔn)確性。

然而,對(duì)于更復(fù)雜的問(wèn)題,這一趨勢(shì)會(huì)發(fā)生變化——解決方案的準(zhǔn)確性會(huì)隨著思考的推進(jìn)而提高,直至達(dá)到某個(gè)閾值。超過(guò)這個(gè)復(fù)雜度閾值,在“崩潰模式”下,模型的準(zhǔn)確率為零。
白婷告訴DeepTech,模型在復(fù)雜問(wèn)題中需要多次推理,在一直沒(méi)有正確解的前提下,模型推理機(jī)制中有可能采用了多次迭代推理生成效率優(yōu)化策略,或許是防止迭代過(guò)多的一種資源保護(hù)策略。因此,本次論文中的發(fā)現(xiàn)需要從模型實(shí)現(xiàn)層面去進(jìn)行細(xì)致的分析和驗(yàn)證。
白婷指出,大模型的推理過(guò)程本質(zhì)上是記憶模式的調(diào)用也是有可能的。對(duì)于DeepSeek-R1、o3-mini這類模型,其表現(xiàn)高度依賴訓(xùn)練數(shù)據(jù)中記憶模式的覆蓋范圍,當(dāng)問(wèn)題復(fù)雜度突破記憶模式的覆蓋閾值(如本次蘋果研究團(tuán)隊(duì)設(shè)計(jì)的可控謎題環(huán)境),模型便陷入“零準(zhǔn)確率”狀態(tài)。
雖然本次謎題環(huán)境允許對(duì)問(wèn)題復(fù)雜度進(jìn)行細(xì)粒度控制的受控實(shí)驗(yàn),但它們僅代表推理任務(wù)的一小部分,可能無(wú)法捕捉到現(xiàn)實(shí)世界或知識(shí)密集型推理問(wèn)題的多樣性。
需要指出的是,本研究主要基于黑箱API訪問(wèn)封閉的前沿大推理模型,這一限制使研究團(tuán)隊(duì)無(wú)法分析其內(nèi)部狀態(tài)或架構(gòu)組件。
此外,使用確定性謎題模擬器時(shí),研究團(tuán)隊(duì)假設(shè)推理可以一步一步地得到完美驗(yàn)證。然而,在結(jié)構(gòu)化程度較低的領(lǐng)域,這種精確的驗(yàn)證可能難以實(shí)現(xiàn),從而限制了該分析方法向更廣泛推理場(chǎng)景的遷移。
總的來(lái)說(shuō),研究團(tuán)隊(duì)通過(guò)可控的解謎環(huán)境,從問(wèn)題復(fù)雜度的角度考察了前沿大型推理模型。這一成果揭示了當(dāng)前模型的局限性:即盡管它們擁有復(fù)雜的自我反思機(jī)制,但這些模型在超過(guò)特定復(fù)雜度閾值后,仍然無(wú)法發(fā)展出可泛化的推理能力。研究團(tuán)隊(duì)認(rèn)為,本次成果或許能為研究這些模型的推理能力鋪平道路。